<小川卓が解説!>まずは実践!CRM第3回:ユーザーの「分類」を考える

UNCOVER TRUTHのChief Analytics Officer の小川です。このシリーズでは、まずは実践!という事で、なるべくハードルが低い「CRM」の実践方法について全6回でお送りしていきます。CRMというと難易度が高そう!というイメージを持たれる方も多いかと思いますので、そのハードルを下げて、実際にまずは1回試してみることをゴールにします。
前回は計測するためのデータ取得と設計環境を整える方法についての記事でした。今回は各種ツールでデータを取得出来るようになった後に、ユーザーの分類を行っていきます。そのために必要な「分類」についての知識を今回は学んでいきましょう。
目次
分類とは?
「対象データを分けて特徴付ける」ことです。分類をすることにより、全体像だけではつかめない気づきを発見したり、どの分類に対して施策を行うかを判断したり、施策を行った際にどの分類に影響があったかを把握したり、といったことが可能になります。
例えば以下の数値にどのような気づきがあるでしょうか?
営業アポ件数 100件
受注数 30件
転換率が30%であることは分かりますが、それ以外の事は分かりませんよね。しかし、以下のようにデータを分類した場合はどうでしょうか?
電話営業経由のアポ件数 70件
セミナー経由のアポ件数 30件
電話営業経由の受注数 7件
セミナー経由の受注数 9件
データを分類する事で違いを発見する事が出来、次の戦術(セミナー経由のアポ件数を増やそう、電話営業の質を改善しよう)に繋がります。
このようにデータを分類する事で、施策の優先順位決め・アイデア出し・評価が行えることが、分類の価値でありCRMとも非常に相性がいいのです。全体ではわからない事、個別では細かすぎることを分類する事で解決できます。
2種類の分類方法
分類には2つの方法があり、それぞれの特徴や違いを理解しておく必要があります。自社としてどちらの分類を行うのかを考えてみましょう。
2種類の分類とは、「セグメント」そして「クラスタリング」です。それぞれどちらも分類をするための手法ですが違いを説明できるでしょうか?それぞれ詳しく見ていきましょう。
セグメントとは?
データを特定の属性や行動別に分けて特徴を把握します。何で分類をするかに関しては分析する側が意図的に決めます。
例えば「営業の獲得経路」「サイト内の特定コンテンツの閲覧・未閲覧」「クライアント会社規模」「都道府県」等が考えられます。分類するべき項目を決めたら、それにあわせてユーザー(あるいは企業)をふるい分けていきます。
例えば100社契約していたとしたら「会社規模大(月間売上1億円以上)」「会社規模(月間売上1000万円~5000万円)」「会社規模小(月間売上1,000万円未満)」といった具合です。このデータ自体はSFAやCRM登録しておき、分類に応じて集計、分析、施策の実行をします。
どのような「セグメント」を使えば良いかは、「分類ごとに異なる施策を行うか」によって変わってきます。先ほどの会社規模の例であれば「会社規模ごとにセミナーの案内・メール配信内容・営業の仕方」を変えるか否かということです。
このように分類した先の施策をイメージしないと改善には活かせません。分析をして施策を見つけてくることも可能なので(例えば会社規模大の流入はどこが一番多いのかなど)セグメントを作成する場合は、分析と施策を先にイメージしておきましょう。
先ほどの例で具体的なライン(どこからが大企業・中企業・小企業なのか)が決められない場合は、デシル分析なども有効でしょう。上位X%が売上のY%を占めかを確認し、それに応じて「上位X%」でセグメントを作るといった形です。
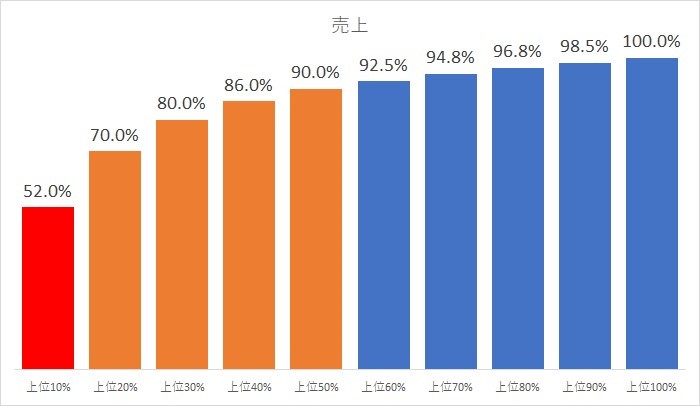
施策に繋がりそうな条件をまずは3つほど選んでセグメントをしてみましょう。
クラスタリングとは?
データをロジックによっていくつかのグループに分けていくのがクラスタリングの手法になります。一度分析をしてデータがグループ化された後に、分けられた根拠やその特徴を探り、グループの意味を考えるというアプローチです。
つまりどのラインで分類するか(あるいはケースによってはどの項目で分類するか)を事前に決めずに行うという手法です。
あるゴール「成約した・成約していない」に対して、何故そうだったのかの説明変数を求めるというのもクラスタリングの1つの方法です。デンドログラムの形(階層型クラスタリング)で表現されることが多いです。
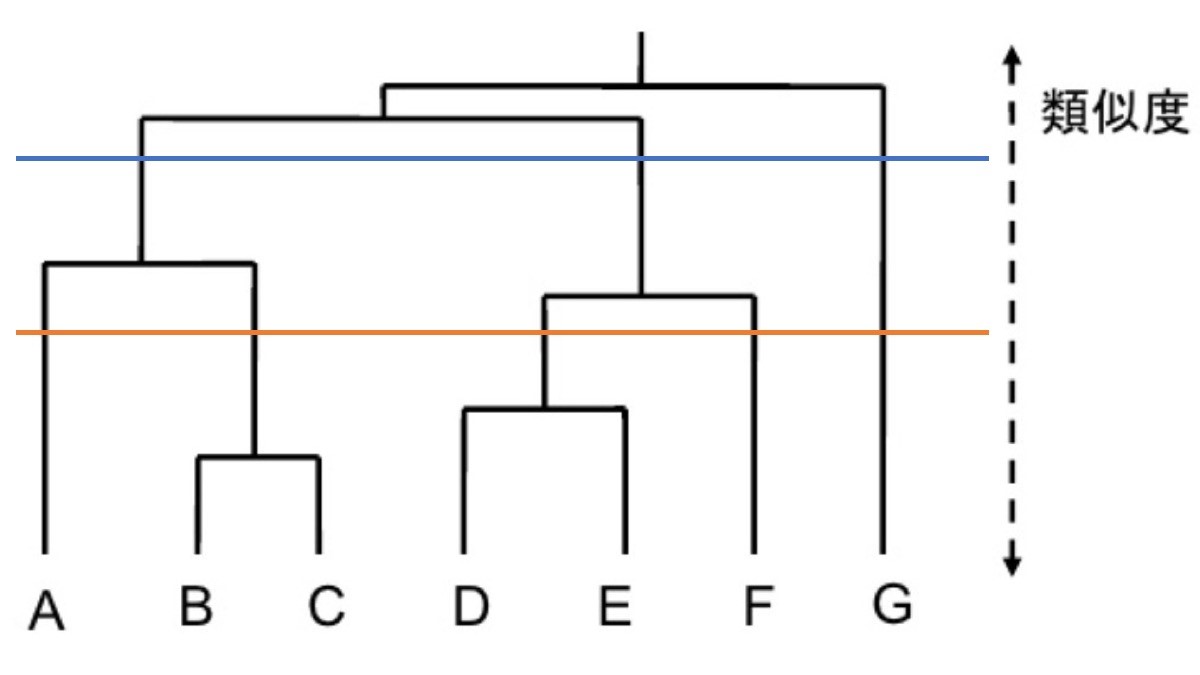
クラスタが作成されていく際の結合の過程を現したものになります。3つのクラスタに分けたい場合は青い線の部分、5つのクラスタに分けたい場合は青い線の部分で分類する形になります。
例えば青い線の場合は「A・B・Cを含む分類1」「D・E・Fを含む分類2」「Gを含む分類3」という形にあります。分岐の所に分岐条件が入ります。実際に追加してみたのでご覧ください。
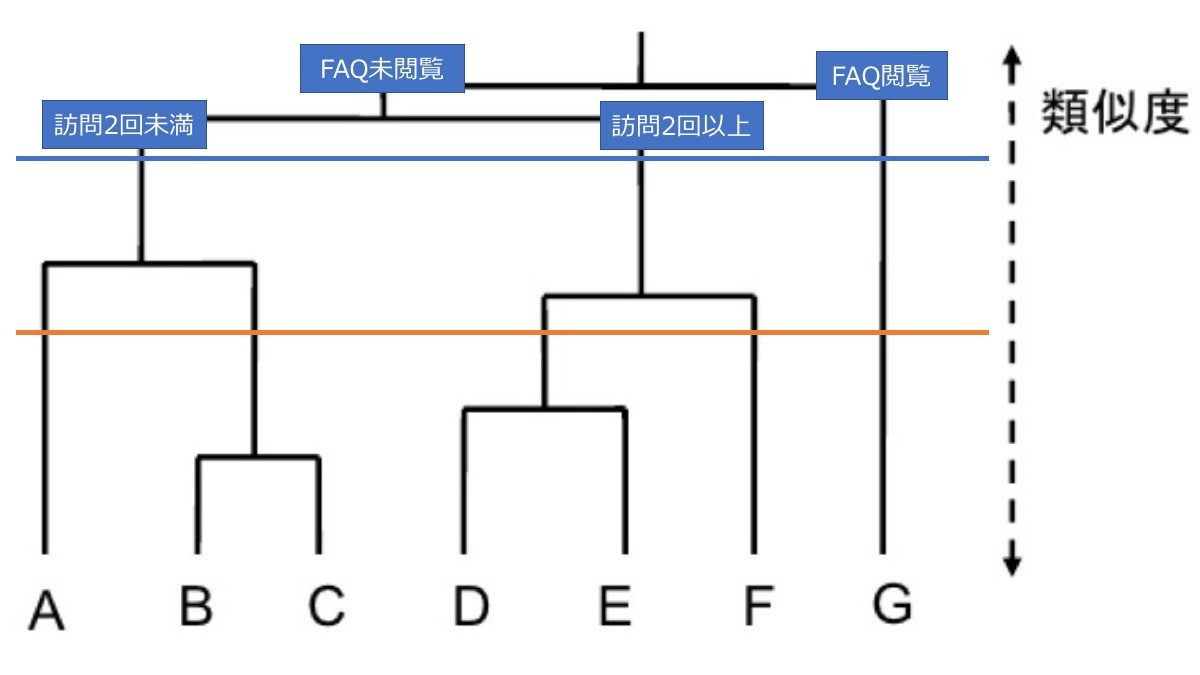
例えばA→Gに向かうに連れCV率が高くなるクラスタだとすれば、CVにまず影響を与えているのが「FAQ閲覧の有無」そしてその次に「訪問回数が2回以上か否か」という事になります。
何が分岐の条件として利用されるかは、分析をする元データ(説明変数の内容と種類)に依存する形になります。なんでもデータを取り込めば良いという事では無く、やはり施策に活かせる変数を使うとよいでしょう。
他にも非階層型のK-Means法などを利用してクラスタリングをする方法もあります。こちらは先にクラスタ数を決め、それの数にあわせてクラスタを作ってくれるという手法になります。
こういった分析を行うにはBIツールなどが必要になってきます。上記のクラスタもTableauを使った分類になっています。
どちらの方法を使えばよいのか?
正解があるわけではありません。社内で分類に使う項目やしきい値が明確な場合はセグメントが良いでしょうし、そのあたりが不明確な場合はクラスタリングが良いでしょう。
最後に
どちらの方法を使ったとしても大切なのは出てきた分類に紐づく条件に対して、分析や施策が行えることです。ぜひ分類後をイメージしながら分類の作業に取り組んでみましょう。次回は分類の実例やその後の分析に関する話になります。

- 小川 卓
- 株式会社UNCOVER TRUTH
- CAO(Chief Analytics Officer)
Webアナリストとしてマイクロソフト・ウェブマネー・リクルート・サイバーエージェント・アマゾンジャパンなどで勤務。解析ツールの導入・運用・教育、ゴール&KPI設計、施策の実施と評価、PDCAをまわすための取り組みなどを担当。全国各地で講演を毎年40回以上行っている。デジタルハリウッド大学大学院客員教授。 主な著書に『ウェブ分析論』『ウェブ分析レポーティング講座』『マンガでわかるウェブ分析』『Webサイト分析・改善の教科書』『あなたのアクセスはいつも誰かに見られている』『「やりたいこと」からパッと引ける Google アナリティクス 分析・改善のすべてがわかる本』など。
UNCOVER TRUTHでは様々な業界の企業さまのWeb事業を成長させるお手伝いをさせていただいております。Webサイト改善についてご興味がございましたら、ぜひお気軽にお問い合わせください 。