データエクスポート機能とは、Content Analyticsで取得した行動ログ等をCSV形式で出力する機能です。
ページレポートやコンテンツレポートで集計される前の生データを出力することができるため、これらのデータをCRMやMAツールに連携することで、より高度な分析を行うことが可能です。
なお、行動ログはデータ量が膨大なため、組織専用のGoogle Cloud Platform(以下GCP)を作成し、日次でエクスポートされます。
エクスポートの設定は、組織管理画面の「データエクスポート」画面で実施します。
GCPサービスアカウントの作成・削除

データエクスポート機能をご利用いただくには、最初にGCPサービスアカウントの作成を行います。
①GCPサービスアカウントの作成
「GCPサービスアカウントの作成」をクリックして、キーファイル作成画面を開きます。
②「作成」を選択
作成ボタンをクリックすると、GCPサービスアカウントが作成され、接続に必要なキーファイルをダウンロードすることができます。
説明の入力は任意です。必要に応じて、利用者名などを入力してください。
③キーファイルのダウンロード
GCPサービスアカウントの作成が完了すると、自動的にキーファイルのダウンロードが始まります。
任意の場所にjsonファイルを保存してください。
キーファイルは、本画面のみで発行し、再発行はできませんので、大切に保管してください。
④作成画面を閉じる
キーファイルを保存すると、サービスアカウント作成完了画面が表示されます。
「閉じる」をクリックして画面を閉じます。
⑤GCPサービスアカウント情報
GCPサービスアカウントの作成が完了すると、GCPサービスアカウント情報が表示されます。![]() をクリックすると、発行したGCPサービスアカウントを削除することができます。
をクリックすると、発行したGCPサービスアカウントを削除することができます。
GCPサービスアカウントを削除すると、出力済みの全てのデータが破棄されますので十分にご注意ください。
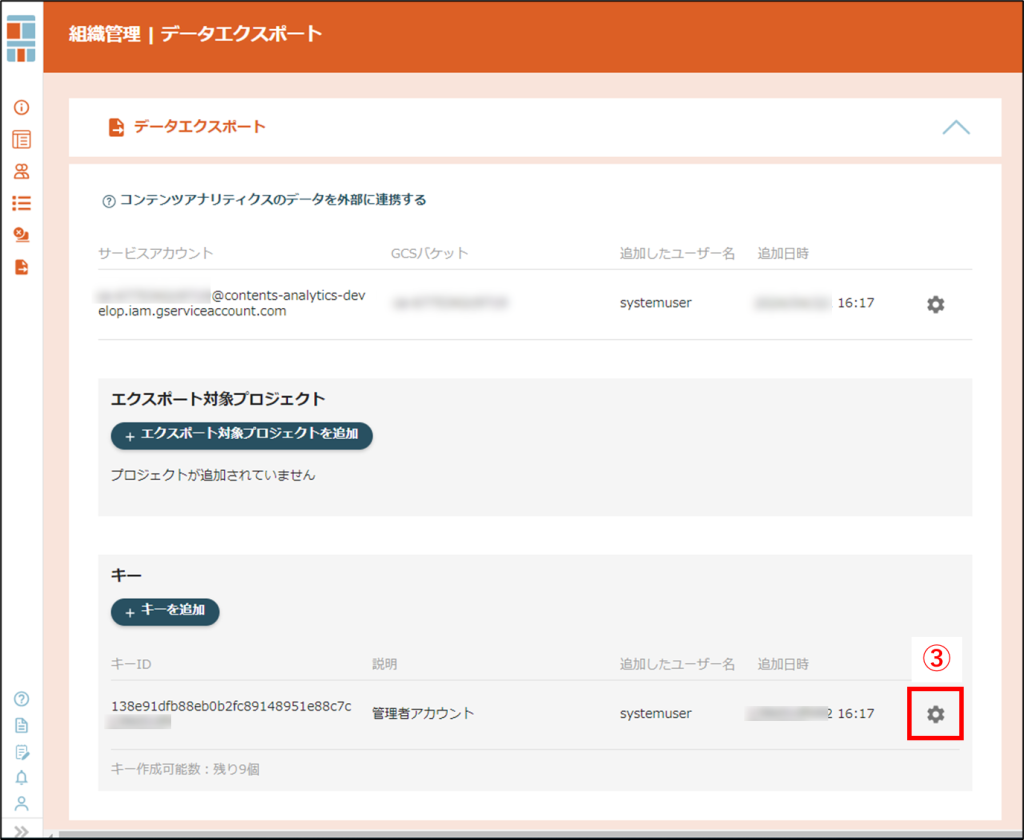
キーファイルの追加発行・変更・削除
キーファイルの追加発行・変更・削除が可能です。
GCPサービスアカウントにアクセスするユーザーを追加する場合は、新たにキーファイルを発行してください。
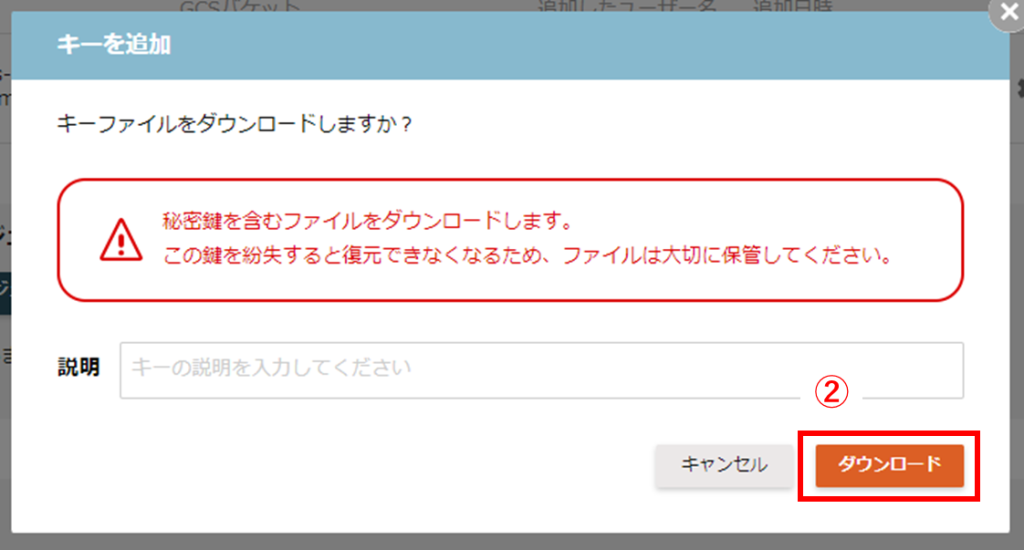
①キーを追加
「キーを追加」をクリックして、キーファイル作成画面を開きます。
②「ダウンロード」を選択
ダウンロードボタンをクリックすると、新しいキーファイルのダウンロードが始まります。
任意の場所を選択して、jsonファイルをダウンロードしてください。
キーファイルは、本画面のみで発行し、再発行はできませんので、大切に保管してください。
説明の入力は任意です。必要に応じて、利用者名などを入力してください。
③説明の変更・キーファイル削除
![]() をクリックすると、説明の変更と、キーファイルの削除をすることができます。
をクリックすると、説明の変更と、キーファイルの削除をすることができます。
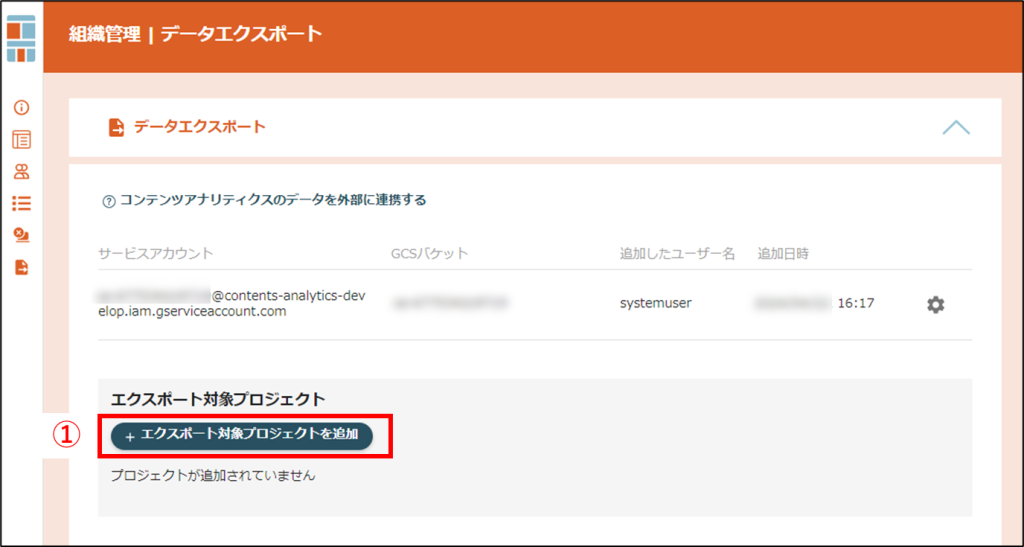
エクスポート対象プロジェクト
行動ログを出力する対象プロジェクトを設定します。
①エクスポート対象プロジェクトを追加
「エクスポート対象プロジェクトを追加」をクリックします。
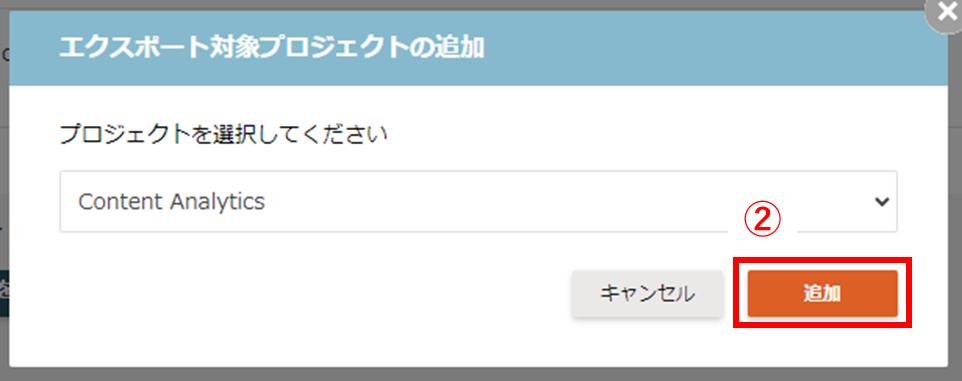
②プロジェクトの追加
行動ログを追加するプロジェクトをプルダウンから選択し、「追加」をクリックしてください。
③エクスポート対象プロジェクト情報
エクスポート対象プロジェクトの登録が完了しました。
設定完了の翌日以降、毎日AM2:00〜AM6:00にデータが出力されます。
詳しくは、データエクスポートの仕様を確認してください。
データエクスポートの仕様
データエクスポート機能で出力されるデータ、データエクスポート処理の仕組み、ファイル構造についてご紹介します。
出力されるデータ
データエクスポートで出力されるデータには、3種類のイベントデータと、コンテンツレポート画面で登録したコンテンツマスタ・コンタンツタグ情報が含まれています。
| データ種類 | 説明 | |
| タグイベントデータ | ページビュー | ページ閲覧を検知するイベント。以下のページ単位の情報を保持する。 1. 閲覧されたページURL・タイトルなど、ページ単位の情報 2. タグに設定したユーザーID・カスタムディメンションの情報 |
| コンテンツイベント | ページビュー単位のコンテンツイベント。以下のコンテンツ単位の情報を保持する。 1. コンテンツの閲覧秒数 2. コンテンツのクリック数 ※1ページビューにつき、閲覧・クリックされたコンテンツ分のデータが複数存在する。 |
|
| カスタムイベント | 任意のタイミングで発火させたイベント。以下の情報を保持する。 1. タグに設定したカスタムイベントの値(カテゴリ・アクション・ラベル・値) ※1ページビューにつき、発火したイベント分のデータが複数存在する |
|
| コンテンツマスタ | コンテンツレポートで登録したコンテンツ名 | |
| コンテンツタグデータ | コンテンツレポートで登録したコンテンツに紐づくタグ情報 | |
データエクスポート処理の仕様
データエクスポートはサービスアカウント作成・対象プロジェクト設定の翌日から開始されます。
AM2:00〜AM6:00の間でエクスポート処理が実行されるため、AM6:00以降にダウンロードを開始してください。
| スケジュール | 日次 AM02:00~AM06:00 | |
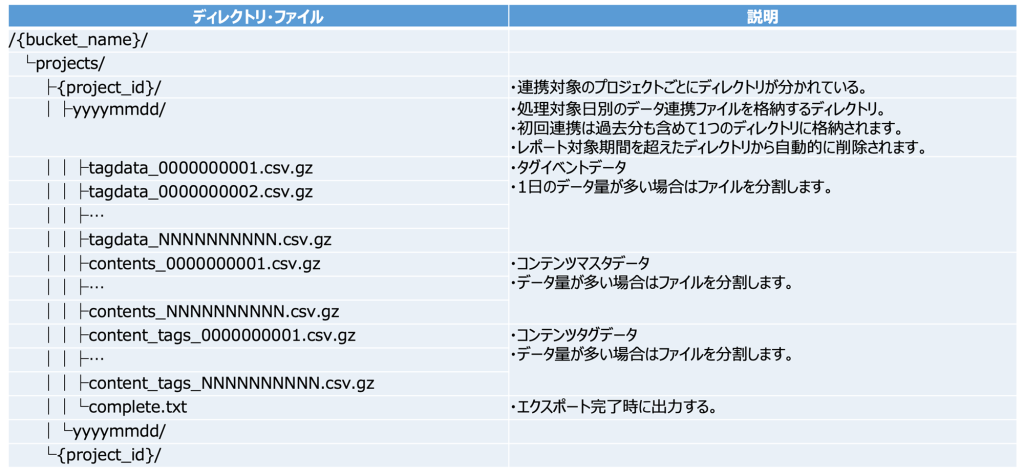
| ディレクトリ構成 | 処理日ごとのエクスポートデータは1つのディレクトリに格納されます。(フォルダ名:YYYYMMDD) | |
| エクスポート仕様 | タグイベントデータ | ・ファイル名:tagdata_*.csv.gz ・日付を跨ぐデータ、または、1日のデータ量が多い場合はファイルを分割します。 ・データ量が膨大なため、増分データのみエクスポートします。 ・初回:全件(レポート対象期間分のデータ(最大400日) ・初回以降:増分データのみ |
| コンテンツマスタ | ・ファイル名:contents_*.csv.gz ・日次で全件データエクスポートします。(データを削除した場合は次回のデータ連携ファイルから含まれません) |
|
| コンテンツタグデータ | ・ファイル名:contents_tags_*.csv.gz ・日次で全件データエクスポートします。(データを削除した場合は次回のデータ連携ファイルから含まれません) |
|
| 処理正常終了判定 | 処理が正常終了した場合、処理日フォルダ配下にcomplete.txtを作成します。所定時間(AM06:00)までの間にcomplete.txtファイルが存在しない場合は、異常終了or遅延している可能性があります。その際はお問い合わせください。 | |
※1 レポート対象期間とは、ContentAnalyticsのページレポート・コンテンツレポート閲覧可能な期間のこと。
ファイル構造
a. エクスポートファイル共通仕様
| ファイル形式 | CSV |
| 区切り文字 | カンマ |
| 囲み文字 | ダブルクォート 文字列にカンマ・ダブルクォート・改行などがあり、必要な場合のみ付与される |
| 文字コード | UTF-8 |
| 改行コード | LF |
| ヘッダー | あり(1行目) |
| エスケープ文字 | 文字にダブルクォートがある場合、ダブルクォートでエスケープする |
今後ファイルに項目を追加する場合は、最終列の後ろに追加します。
BigQueryのCSVインポートオプションでは、以下のオプションの設定を推奨します。
allowJaggedRows=true: 過去に出力されたエクスポートファイルが、取り込み先のスキーマとアンマッチでも取り込みエラーを防ぐためignoreUnknownValues=true: エクスポートファイルに新規項目が追加され、取り込み先のスキーマが新規項目未対応でも取り込みエラーを防ぐため
ページタイトルなどに改行を含めることも可能なため、BigQueryのCSVインポートオプションでは、以下のオプションの設定を推奨します。
allowQuotedNewlines=true: ページタイトルなどのSTRING項目に改行が含まれていても取り込みエラーを防ぐため
BigQueryのCSVインポートオプションの詳細は以下をご確認ください。
Cloud StorageからのCSVデータの読み込み
(Google Cloudのヘルプページへ遷移します)
b. 各エクスポートファイルの項目
ファイル名:tagdata_*.csv.gz
| フィールド名 (論理名) |
データ型 | 説明 |
| event_id (タグイベントID) |
string | ・レコードごとに割り当てた32文字のランダムな英数字(UUIDv4で算出) ※エクスポートデータに更新データを含む場合、更新の結合キーとしてご活用ください |
| timestamp (イベント発火日時) |
datetime (ISO8601) |
・タグでイベントが発火した日時 ・形式: YYYY-MM-DDThh:mm:ssZ(ISO8601準拠、タイムゾーンはUTC) |
| project_id (プロジェクトID) |
integer | ・プロジェクトを識別するID |
| session_id (セッションID) |
string | ・セッションを識別するID ・セッション内の各ページビューを紐づける際に使用 ・Cookieに値を保持している(有効期間: 30分) ・32文字のランダムな英数字(UUIDv4で算出) |
| view_id (ページビューID) |
string | ・ページビューを識別するID ・ページビュー(page_view)のデータと各イベントデータ(content_view・custom_event)を紐づける際に使用 ・32文字のランダムな英数字(UUIDv4で算出) |
| client_idclient_id (クライアントID) |
string | ・エンドユーザの訪問を識別するID ・Cookieに値を保持している(有効期間: 2年) ・32文字のランダムな英数字(UUIDv4で算出) |
| user_id (ユーザーID) |
string | ・ユーザを識別するID ・デバイス/ブラウザをまたいだユーザの行動を計測できるようになり、分析精度が向上します。 ・スコープ「ユーザー」の概念で値をセットするため、レコードが複数日に渡って更新データとして連携される可能性あり 例)セッション後半のページビューでユーザーIDがセットされた場合、前半のページビューにも遡って値をセットする |
| normalized_url (URL(正規化済)) |
string | ・計測対象ページのURL。集計の精度を高めるために以下の仕様でURLを加工 1. 末尾スラッシュを削除 2. ContentAnalyticsで許可したパラメータのみ付与(パラメータ名の昇順で並び替え) ※ContentAnalyticsのコンテンツレポートなどに表示しているURLはこちらの値 |
| original_url (URL(オリジナル)) |
string | ・計測対象ページのURL(未加工) |
| title (タイトル) |
string | ・計測対象ページのタイトル |
| device (デバイス) |
string | ・訪問時のデバイスを識別する値。値の種類は以下の通り。 1. mobile: モバイル 2. pc: PC |
| event_type (イベントタイプ) |
string | ・イベントの種類を識別する値。値の種類は以下の通り。 1. page_view: ページビューイベント 2. content_event: コンテンツイベント 3. custom_event: カスタムイベント |
| content_id (コンテンツID) |
string | ・コンテンツを識別するID(コンテンツレポートでコンテンツごとに表示されているID) ・10文字のランダムな英数字 ・閲覧もクリックもされていないコンテンツはレコードが存在しない。 |
| second (閲覧秒数) |
integer | ・コンテンツの閲覧秒数 ・ページビュー単位の集計レコードのため、レコードが複数日に渡って更新データとして連携される可能性あり 例)6/1の連携では「30」、6/2の連携では「60」など。(更新データは複数回に渡って連携される) |
| clicks_count (クリック数) |
integer | ・コンテンツのクリック数 ・ページビュー単位の集計レコードのため、レコードが複数日に渡って更新データとして連携される可能性あり 例)6/1の連携では「1」、6/2の連携では「2」など。(更新データは複数回に渡って連携される) |
| dimension1 (カスタムディメンション1) |
string | ・タグにセットしたカスタムディメンションの値 ・スコープ"ユーザー"の場合は、content_view、custom_eventにも値をセット (ユーザーIDがセットされる可能性があるため、user_idと同じ粒度で値をセットする) ・スコープ「セッション」または「ユーザー」の場合は、レコードが複数日に渡って更新データとして連携される可能性あり 例)セッション後半のページビューでカスタムディメンションがセットされた場合、前半のページビューにも遡って値をセットする |
| dimension2 (カスタムディメンション2) |
string | 同上 |
| dimension3 (カスタムディメンション3) |
string | 同上 |
| dimension4 (カスタムディメンション4) |
string | 同上 |
| dimension5 (カスタムディメンション5) |
string | 同上 |
| dimension6 (カスタムディメンション6) |
string | 同上 |
| dimension7 (カスタムディメンション7) |
string | 同上 |
| dimension8 (カスタムディメンション8) |
string | 同上 |
| dimension9 (カスタムディメンション9) |
string | 同上 |
| dimension10 (カスタムディメンション10) |
string | 同上 |
| dimension11 (カスタムディメンション11) |
string | 同上 |
| dimension12 (カスタムディメンション12) |
string | 同上 |
| dimension13 (カスタムディメンション13) |
string | 同上 |
| dimension14 (カスタムディメンション14) |
string | 同上 |
| dimension15 (カスタムディメンション15) |
string | 同上 |
| dimension16 (カスタムディメンション16) |
string | 同上 |
| dimension17 (カスタムディメンション17) |
string | 同上 |
| dimension18 (カスタムディメンション18) |
string | 同上 |
| dimension19 (カスタムディメンション19) |
string | 同上 |
| dimension20 (カスタムディメンション20) |
string | 同上 |
| event_category (イベントカテゴリ) |
string | ・任意のタイミングでカスタムイベントとして発火されたカテゴリ |
| event_action (イベントアクション) |
string | ・任意のタイミングでカスタムイベントとして発火されたアクション |
| event_label (イベントラベル) |
string | ・任意のタイミングでカスタムイベントとして発火されたラベル |
| event_value (イベント値) |
number | ・任意のタイミングでカスタムイベントとして発火された値 |
| created_at (レコード登録日時) |
datetime (ISO8601) |
・エクスポート用テーブルにレコード登録された日時 ・形式: YYYY-MM-DDThh:mm:ssZ(ISO8601準拠、タイムゾーンはUTC) |
| updated_at (レコード更新日時) |
datetime (ISO8601) |
・エクスポート用テーブルにレコード更新された日時 ・形式: YYYY-MM-DDThh:mm:ssZ(ISO8601準拠、タイムゾーンはUTC) |
| ssc_id (サーバサイドCookieID) |
string | ・エンドユーザの訪問を識別するID ・Cookieに値を保持している(有効期間: 2年) ・32文字のランダムな英数字(UUIDv4で算出) |
ファイル名:contents_*.csv.gz
| フィールド名 (論理名) |
データ型 | 説明 |
| content_id (コンテンツID) |
string | ・コンテンツを識別するID(コンテンツレポートでコンテンツごとに表示されているID) ・10文字のランダムな英数字 |
| project_id (プロジェクトID) |
integer | ・プロジェクトを識別するID |
| url (ページURL) |
string | ・コンテンツのURL |
| name (コンテンツ名) |
string | ・コンテンツの名称 |
| created_at (レコード登録日時) |
datetime (ISO8601) |
・レコード登録された日時 ・形式: YYYY-MM-DDThh:mm:ssZ(ISO8601準拠、タイムゾーンはUTC) |
| updated_at (レコード更新日時) |
datetime (ISO8601) |
・レコード更新された日時 ・形式: YYYY-MM-DDThh:mm:ssZ(ISO8601準拠、タイムゾーンはUTC) |
ファイル名:contents_tags_*.csv.gz
| フィールド名 (論理名) |
データ型 | 説明 |
| content_id (コンテンツID) |
string | ・コンテンツを識別するID(コンテンツレポートでコンテンツごとに表示されているID) ・10文字のランダムな英数字 |
| project_id (プロジェクトID) |
integer | ・プロジェクトを識別するID |
| name (タグ名) |
string | ・コンテンツタグの名称 |
c. GoogleCloudStorageのディレクトリ構成
補足事項
- データエクスポート用のサービスアカウントを作成すると、専用のデータ連携バケットをGCS内に作成します(他サービスアカウントからアクセス不可)。そのため、サービスアカウント削除→新規作成をすると、これまで出力されたファイルにはアクセスできなくなり、新たに初回連携分のデータをエクスポートします(初回はレポート対象期間分のデータをまとめて出力)。
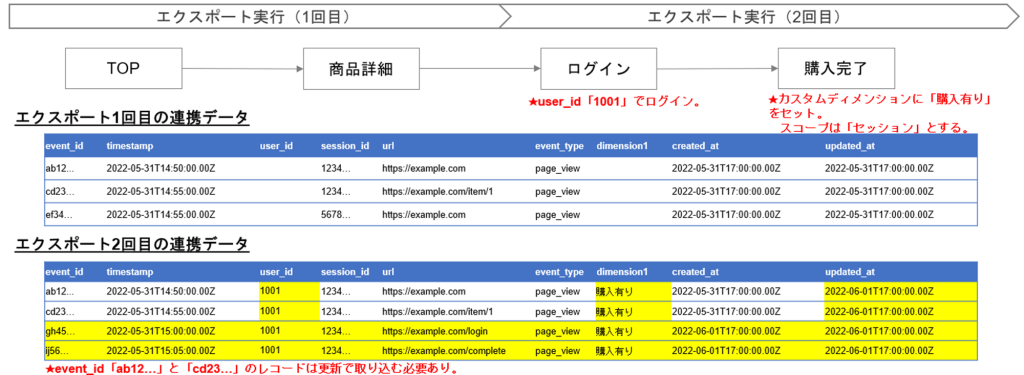
- セッション内の途中でユーザID、またはスコープ”セッション”or”ユーザー”のカスタムディメンションがセットされた場合、既に連携済みのデータがレコード更新対象となるケースがあります。
(詳細は「補足事項:a.更新データの取り込みについて」を参照してください。
- 連携するタグイベントデータファイルは、データ量を削減するため、コンテンツイベント、カスタムイベントにページ単位で収集する情報を保持していません。分析時の利便性を考え、事前にデータ加工を推奨します。
詳細は「補足事項:b.分析者のためのタグイベント事前データ加工」を参照してください。
a. 更新データの取り込みについて
ユーザID、またはスコープ”セッション”or”ユーザ”のカスタムディメンションがセットされると、同一セッション内の過去イベントデータ値も更新されます。そのため、tagdataのレコードを特定可能なevent_id項目(uuid形式)をキーにMERGE/UPSERTステートメントなどを使ってインポートしてください。
(新規データは追加、既存データは更新)
※以下にエクスポートをまたがったユーザの行動でユーザIDとカスタムディメンションがセットされた例を提示します。
b. 分析者のためのタグイベント事前データ加工
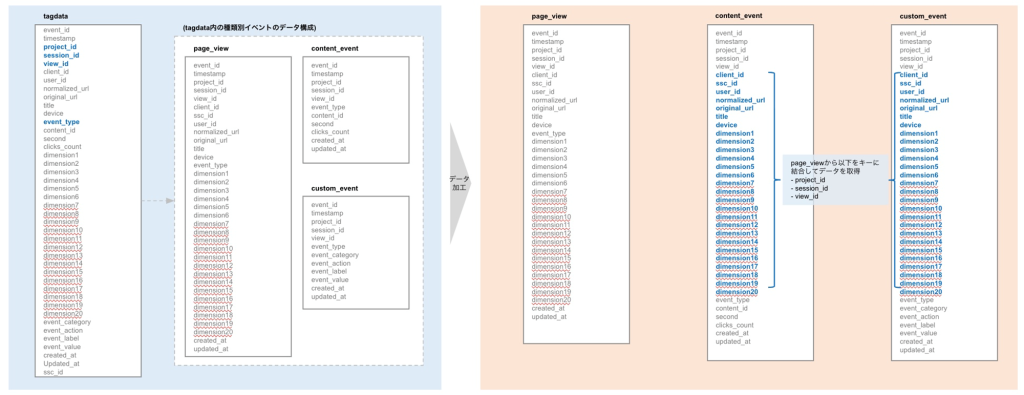
タグイベントデータは、3種類のイベントを1つのデータセットとして連携します。また、コンテンツイベント、カスタムイベントはデータ連携時のデータ量を削減するため、ページ単位で収集する情報を保持していません。一旦CDPなどにtagdataを取り込んだ後、分析時の利便性を考え事前に以下のデータ加工を推奨します。
- イベント単位のテーブルに分割(event_typeにより分割)
- コンテンツイベント、カスタムイベントのレコードにページ単位の情報を付与(project_id, session_id, view_idにより結合)