はじめに
Pythonを使ってTableauのデータを加工できることはご存じでしょうか。今回はTabpyを使ってデータ加工から集計までを行う方法をご紹介します。
Tabpyの使い方
Tabpyとは
Tableau上でPythonが使えるようになるTableauの拡張機能です。Tabpy(Tableau Python Server)という名前からも見て取れるように、TableauがサーバーにアクセスすることでPythonによる計算を可能にしています。
導入方法
①Pythonのインストール
PCへPythonをインストールします。シンプルにPythonを入れる他に、Pythonに関わる便利なものがまとまったAnacondaというパッケージをインストールする方をお勧めします。
➁Tabpy Serverをダウンロード
2つの方法があります。
・Githubからダウンロード
こちらからダウンロード
・Anaconda Promptで以下を実行
pip install tabpy
③Tabpy Serverを立ち上げる
・Githubからダウンロードした場合
Tabpyフォルダから立ち上げます。
・Anaconda Promptを使った場合
「Tabpy」と実行
④Tabpy ServerとTableau Desktopの接続
Tableauでヘルプ➡設定およびパフォーマンス➡拡張機能接続の管理へと進む
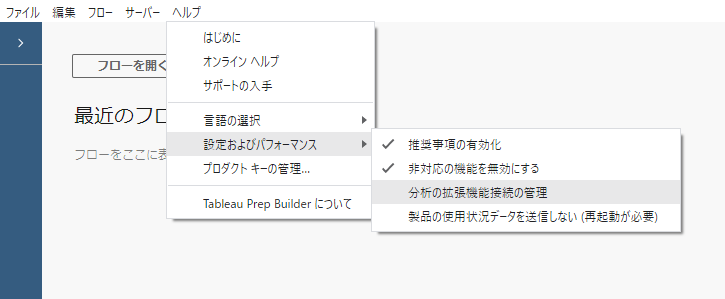
サーバーに「localhost」、ポートに「9004」と入力してサインインします。
実際に使ってみよう!
基本的な4種類の関数
①SCRIPT_REAL 関数
数値を返す関数です。主に数値予測やデータ変換に使用します。
SCRIPT_REAL("import numpy as np; result = np.mean(_arg1); result", SUM([指標]))
この例では、Sales列の平均値を計算しています。
➁SCRIPT_STR 関数
文字列を返す関数です。主に文字列操作やカテゴリデータの処理に使用します。
SCRIPT_STR("import pandas as pd; result = 'High' if _arg1 > pd.Series(_arg2).quantile(0.75) else 'Low'", [Sales], [Sales])
この例では、Salesの値が第75パーセンタイルよりも高い場合に”High”を返し、そうでない場合に”Low”を返します。
③SCRIPT_BOOL 関数
真偽値を返す関数です。主に条件付きフィルタリングや条件付き集計に使用します。
SCRIPT_BOOL("import numpy as np; result = True if _arg1 > np.mean(_arg2) else False", [Sales], WINDOW_AVG([Sales]))
この例では、Salesがそのウィンドウの平均値よりも大きい場合にTrueを返します。
➃SCRIPT_INT 関数
整数値を返す関数です。主に離散値の計算やインデックスの付与に使用します。
SCRIPT_INT("import pandas as pd; result = pd.cut(_arg1, bins=[0, 100, 200, 300], labels=[1, 2, 3])", [Sales])
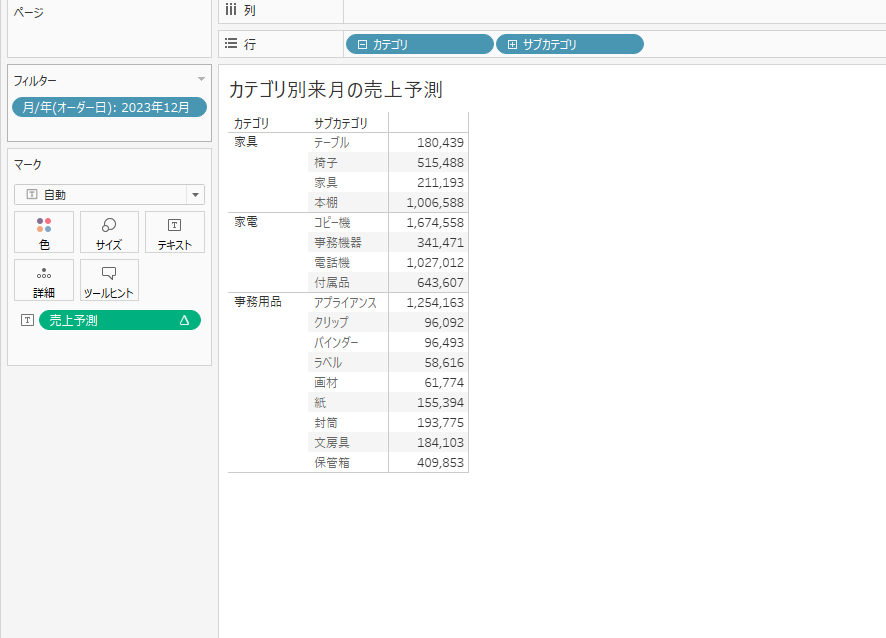
来月の売り上げ予測
それでは上記で紹介した関数を使って簡単な来月の売上予測を出してみます。
SCRIPT_REAL("
import pandas as pd
from sklearn.linear_model import LinearRegression
# データの前処理
data = pd.DataFrame({'売上': _arg1, 'オーダー日': _arg2})
data['オーダー日'] = pd.to_numeric(data['オーダー日'])
# モデルの訓練
X = data[['オーダー日']]
y = data['売上']
model = LinearRegression()
model.fit(X, y)
# 次の月の予測
future_month = [[data['オーダー日'].max() + 1]]
predicted_sales = model.predict(future_month)
return predicted_sales[0]
", SUM([売上]), DATEPART('オーダー日', [オーダー日]))
このように「売上」と「購入日」を渡すと来月の売り上げ予測を返してくれるように書けます。
クラスタリング
クラスタリングをすることも可能です。
SCRIPT_INT("
from sklearn.cluster import KMeans
import pandas as pd
# データの前処理
data = pd.DataFrame({'売上': _arg1, '利益': _arg2})
kmeans = KMeans(n_clusters=3)
data['cluster'] = kmeans.fit_predict(data[['売上', '利益']])
# クラスタを返す
return data['cluster']
", AVG([売上]), AVG([利益]))
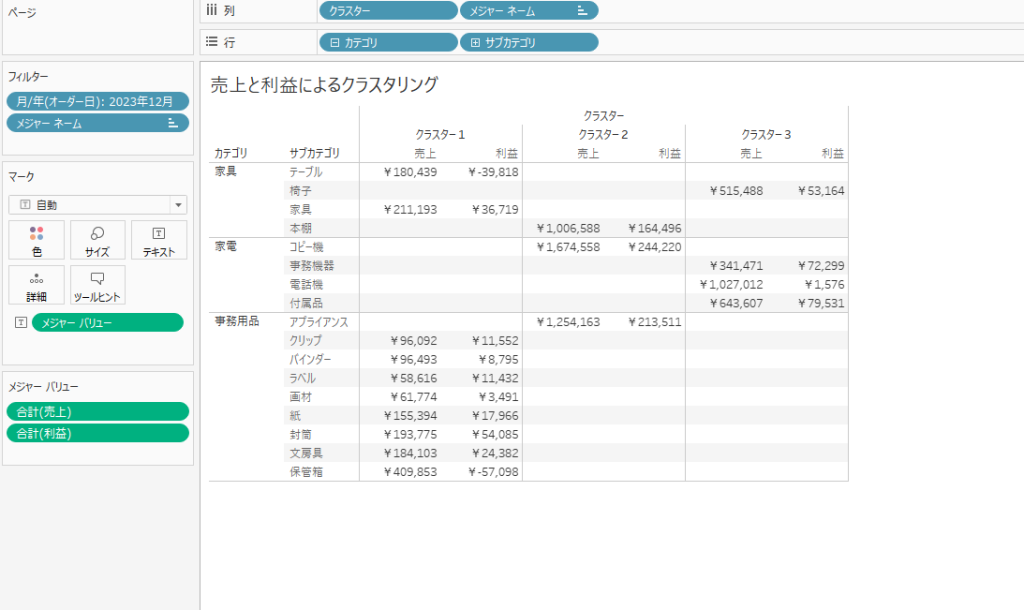
Tableauにはデフォルトでクラスタリング機能が付いていますが、あまりパラメータをいじれなかったり、Kmeans以外のクラスタリングも試したいときに使えます。
まとめ
Tableau上でPythonを使用してデータ集計する方法を紹介しました。今回はNumpyやPandasなどの一般的なライブラリを使用しましたが、Jupyter Notebook上で定義した関数を引っ張ってきてTableau上で活用することもできます。
是非お試しください!
データ活用でお困りの方へ
私たちDX-Accelerator事業では、データ活用についての様々なスキルを持った人材が常駐でデータ活用支援を行うサービスを提供しています。
当事業はローンチから約3年(24年9月時点)ですが、これまでに様々な業界・業種のお客さまのお手伝いをさせていただいております。
少しでも興味を持ってくださったり、すでにご相談をしたいことがある方はお気軽にご相談ください。現在あなたの組織のフェーズがどこにあるかは関係ありません。まずはお話をしましょう。
もう少しサービスについて知りたい方はサービス紹介資料もご用意しています。

お役立ち資料をご活用ください!
データプロフェッショナルであるDXAメンバーが、業務経験をもとにお役立ち資料を作成しています!
おすすめ3選はこちら!
1.GA4 サンプルレポート|Looker Studio 無料プレゼント
GA4の基本KPIが網羅されたテンプレートです!データを差し替えればすぐにご活用いただけます。

2.サンプル経営ダッシュボード | Tableau無料プレゼント
実際にご提供しているダッシュボードをテンプレート化したものです!是非構成やグラフ選択の参考にしてください。

3.データ活用の部長さん必見!データ活用 内製化の正しい進め方
これまでご支援してきた実績をもとに、データ活用の内製化の進め方を解説しています!組織のDXを担われている方、必読です!

以上、おすすめ3選でした!
すべて無料でダウンロードできますので、お気軽にご利用ください。