目次
この記事が解決できること
- JOINとUNIONの違いがわかる
- SQLを書くときに気を付けることが
はじめに
「RDB(リレーショナルデータベース)」を運用・構築する上で、データベース言語である「SQL(Structured Query Language)」の習得は欠かせません。SQLを学習する上で似たような役割を持つクエリがいくつか存在します。
「JOIN」と「UNION」もそのひとつです。
本記事では、JOINとUNIONの違いをサンプルコードを用いて解説します。最後まで読んでいただくと、SQLにおけるJOINとUNIONについて理解を深められます。
データベースの役割について知りたい方は、こちらをご覧ください。

JOINとは
RDBでは、複数の「行(レコード)」と「列(カラム)」で構成された「テーブル」と呼ばれる表でデータを管理しています。
JOINは、複数のテーブルに格納されているデータを関連づけるクエリです。テーブルから特定の行を抽出する「SELECT」と呼ばれる構文で利用されます。
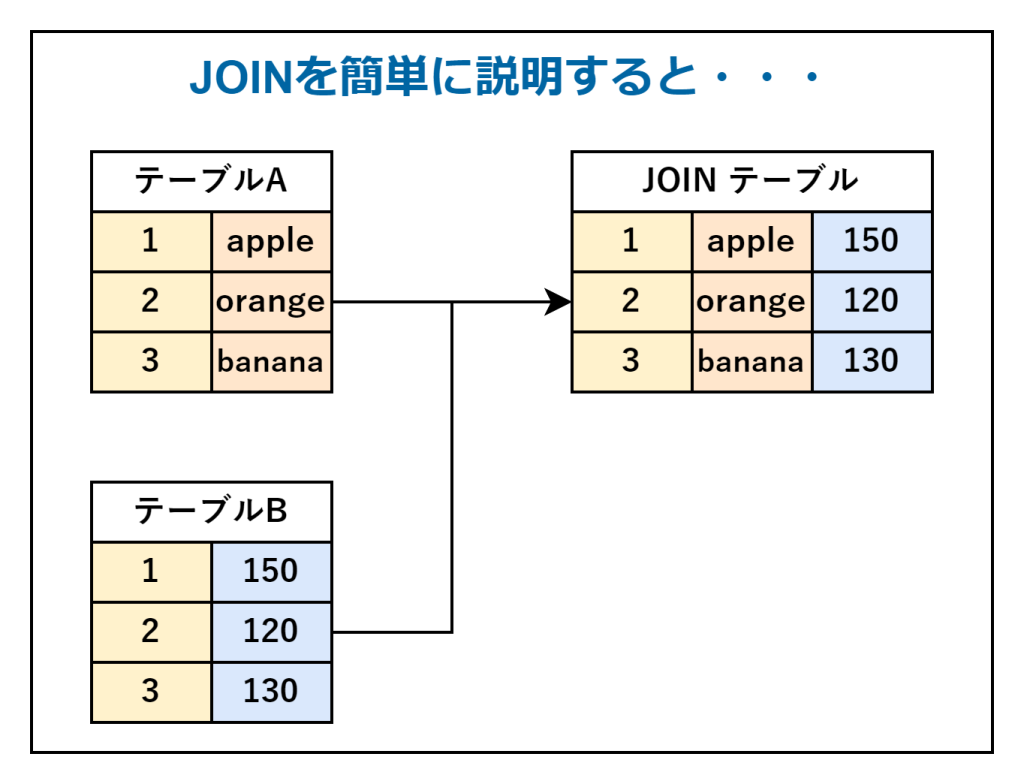
JOINは、以下の3種類に分類されます。
JOINの種類
- INNER JOIN
- LEFT JOIN
- FULL OUTER JOIN
今回は、以下のテーブルを利用してそれぞれの特徴を紹介します。
| employee_id | employee_name |
|---|---|
| 1 | John Doe |
| 2 | Jane Smith |
| 3 | Alice Johnson |
| 4 | Bob Brown |
| employee_id | department_name |
|---|---|
| 1 | Sales |
| 2 | Marketing |
| 3 | HR |
| 5 | IT |
INNER JOIN
「INNER JOIN」は、両方のテーブルに共通する行のみを取得する方法です。共通する行がない場合、その行は結果に含まれません。
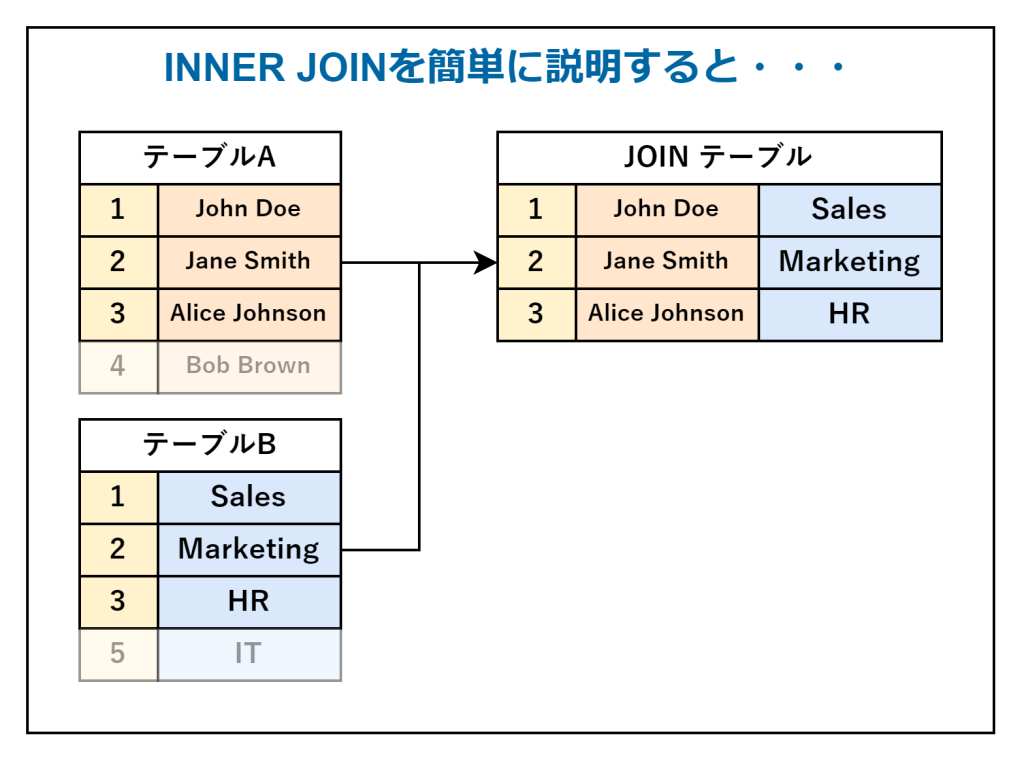
サンプルコードは、以下のとおりです。
SELECT
employees.id AS employee_id,
employees.name AS employee_name,
departments.name AS department_name
FROM
employees
INNER JOIN
departments
ON
employees.employee_id = employee_id;
上記のコードを実行すると、以下のような結果が出力されます。
| employee_id | employee_name | department_name |
|---|---|---|
| 1 | John Doe | Sales |
| 2 | Jane Smith | Marketing |
| 3 | lice Johnson | HR |
LEFT JOIN
「LEFT JOIN」は、テーブルAのすべての行を取得し、テーブルBに一致する行があればそれも一緒に取得する方法です。テーブルBに一致する行がない場合は、その部分にNULLが入ります。
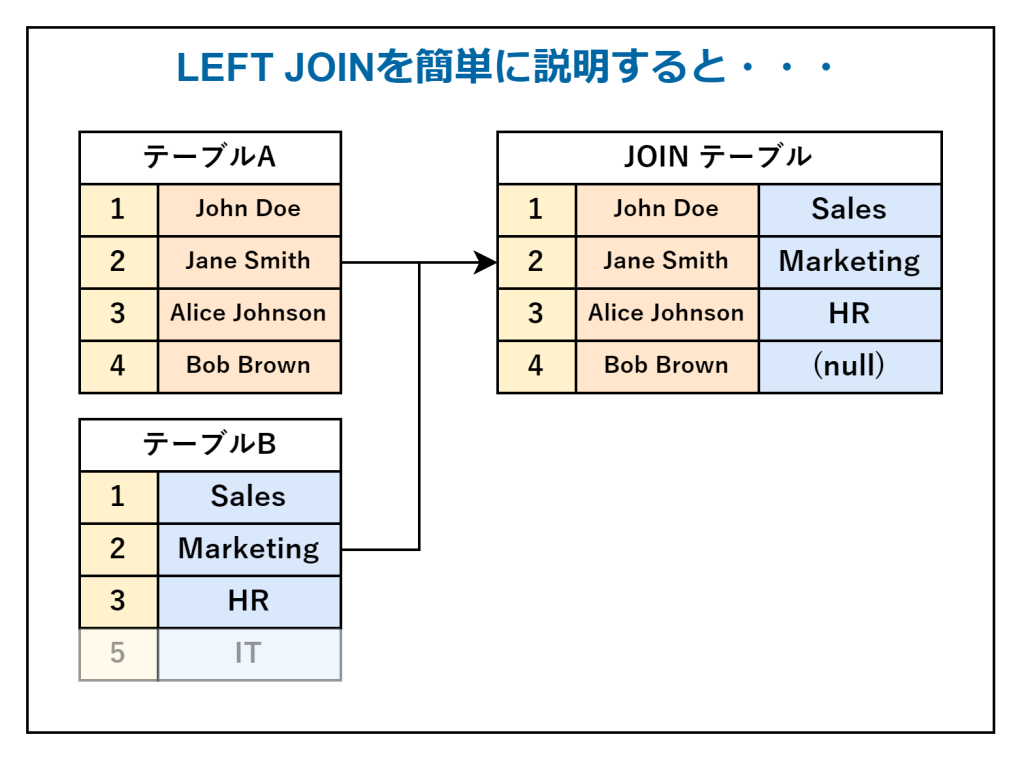
サンプルコードは、以下のとおりです。
SELECT
employees.employee_id AS employee_id,
employees.employee_name AS employee_name,
departments.department_name AS department_name
FROM
employees
LEFT JOIN
departments
ON
employees.employee_id = departments.employee_id;
上記のコードを実行すると、以下のような結果が出力されます。
| employee_id | employee_name | department_name |
|---|---|---|
| 1 | John Doe | Sales |
| 2 | Jane Smith | Marketing |
| 3 | Alice Johnson | HR |
| 4 | Bob Brown | NULL |
FULL OUTER JOIN
「FULL OUTER JOIN」は、両方のテーブルのすべての行を取得し、共通する行があればそれを結合し、共通しない行にはNULLを入れる方法です。テーブルAまたはテーブルBのどちらか一方にしか存在しない行も結果に含まれます。
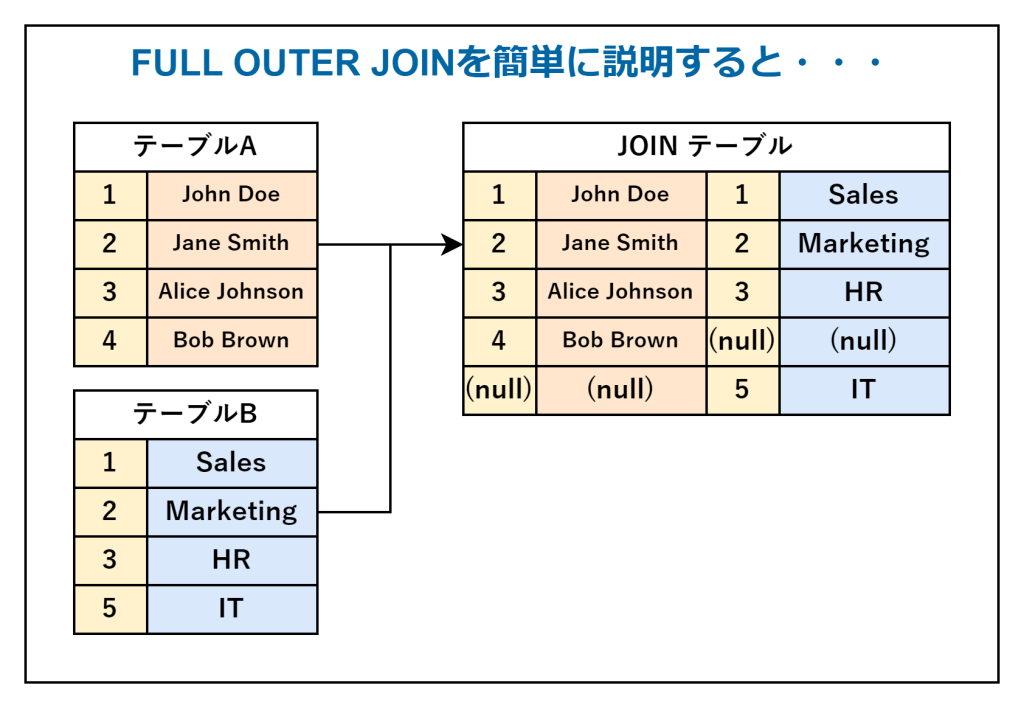
サンプルコードは、以下のとおりです。
SELECT
employees.employee_id AS employee_id_1, --employeesから参照
employees.employee_name AS employee_name,
departments.employee_id AS employee_id_2, --departmentsから参照
departments.department_name AS department_name
FROM
employees
FULL OUTER JOIN
departments
ON
employees.employee_id = departments.employee_id;
上記のコードを実行すると、以下のような結果が出力されます。
| employee_id_1 | employee_name | employee_id_2 | department_name |
|---|---|---|---|
| 1 | John Doe | 1 | Sales |
| 2 | Jane Smith | 2 | Marketing |
| 3 | Alice Johnson | 3 | HR |
| 4 | Bob Brown | NULL | NULL |
| NULL | NULL | 5 | IT |
UNIONとは
UNIONは、SELECTの結果を結合させるクエリです。JOINがテーブル同士を横につなげるのなら、UNIONは縦につなげると思ってもらえれば大丈夫です。
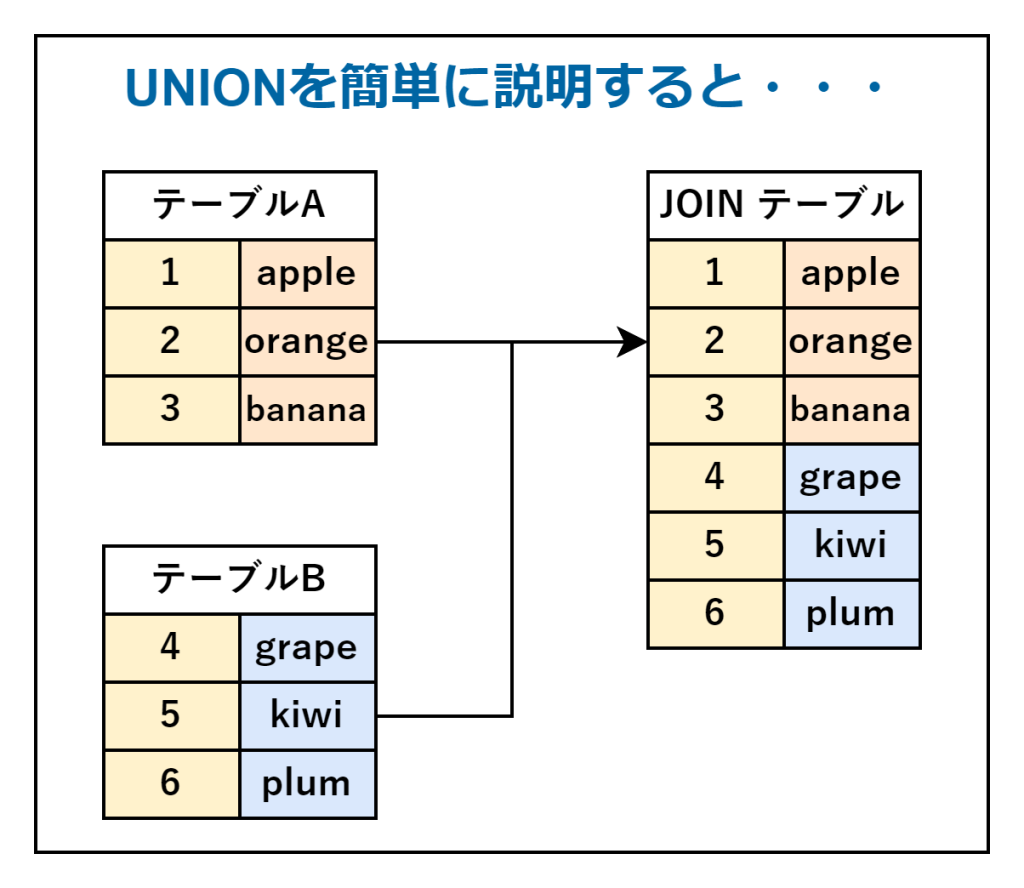
今回は、以下のテーブルを利用してそれぞれの特徴を紹介します。
| employee_name | |
|---|---|
| John Doe | john.doe@example.com |
| Jane Smith | jane.smith@example.com |
| employee_name | |
|---|---|
| John Doe | john.doe@example.com |
| Alice Johnson | alice.johnson@example.com |
| Bob Brown | bob.brown@example.com |
UNIONにはいくつかの種類があるのですが、今回ご紹介するのは頻度の高いものに絞って
・UNION DISTINCT
・UNION ALL
を解説します。
UNION DISTINCTサンプルコードは、以下のとおりです。
SELECT
employee_name,
email
FROM
employees_a
UNION DISTINCT
SELECT
employee_name,
email
FROM
employees_a;
上記のコードを実行すると、以下のような結果が出力されます。
| employee_name | |
|---|---|
| John Doe | john.doe@example.com |
| Jane Smith | jane.smith@example.com |
| Alice Johnson | alice.johnson@example.com |
| Bob Brown | bob.brown@example.com |
「UNION DISTINCT」では、重複した行を削除して結合しますが、「UNION ALL」では、重複している行も含めて結合します。
UNION ALLのサンプルコードは、以下のとおりです。
SELECT
employee_name,
email
FROM
employees_a
UNION ALL
SELECT
employee_name,
email
FROM
employees_b;
上記のコードを実行すると、以下のような結果が出力されます。
| employee_name | |
|---|---|
| John Doe | john.doe@example.com |
| Jane Smith | jane.smith@example.com |
| John Doe | john.doe@example.com |
| Alice Johnson | alice.johnson@example.com |
| Bob Brown | bob.brown@example.com |
JOINとUNIONは組み合わせて利用できる
JOINは複数のテーブルの関連するデータを結合して1つの結果セットにするのに適しており、UNIONは複数のSELECTクエリの結果を1つの結果セットにするのに適しています。それぞれ異なる役割を持っていますが、同時に利用することも可能です。
JOINとUNIONを組み合わせたサンプルコードは、以下のとおりです。
SELECT
employees.employee_id,
employees.employee_name,
_union_t.email
FROM
employees
LEFT JOIN
(
SELECT *
FROM
employees_a
UNION DISTINCT
SELECT *
FROM
employees_b
) AS _union_t
ON
employees.employee_name = _union_t.employee_name
上記のコードの詳細な処理内容は、以下のとおりです。
コードの詳細
- ”employees_a”と”employeesb”をUNION DISTINCT
- ”employees”に対して上記テーブルのemailを付与
上記のコードを実行すると、以下のような結果が出力されます。
| customer_id | employee_name | |
|---|---|---|
| 1 | John Doe | john.doe@example.com |
| 2 | Jane Smith | jane.smith@example.com |
| 3 | Alice Johnson | alice.johnson@example.com |
| 4 | Bob Brown | bob.brown@example.com |
SQLを書くときに注意すること
SQLの基礎知識を身につけたら、実際にコードを書いてみましょう。SQLを書くときは、以下の3点に注意してください。
SQLを書くときの注意点
- 意味を理解する
- テストする
- コメントを残す
意味を理解する
SQLを書くときは、クエリや構文の意味を理解しましょう。
クエリによっては、データベース内のデータを削除したり、大きい負荷を掛けたりするものもあります。理解が不十分な状態で危険なコマンドを実行してしまうと、大きな損失を被ります。
クエリや構文がある場合は、実行する前に確認しましょう。
テストする
SQLを使ってRDBを構築・変更した場合は、リリースする前にテストしてください。
問題なくコーディングできていると感じていても、以下のような理由でうまく実行できない場合があります。
実行がうまくいかない要因
- スペルミス
- 不要なブランクがある
- RDBのバージョンが古い
テストを通じてコードの不備を解消しましょう。
コメントを残す
SQLでは、ソースコードにある特定の箇所をコメントし、実行の際に除外する「コメントアウト」という機能があります。SQLでRDBを構築・変更する場合は、コメントを残しておくと、コードの管理やエラーの特定が効率的になります。
以下のサンプルコードのようにコメントアウトしてみてください。
-- コメントを記入
/*
コメントを記入
*/
/*
コメントを記入
コメントアウト
*/
データ利活用にお悩みの方にはDX-Acceleratorがおすすめ
今回は、JOINとUNIONの違いについて解説しました。
JOINやUNIONなどのクエリを使いこなすことで、RDBに格納されているデータを簡単に管理・操作できるようになります。正しい知識を身につけ、自社のニーズにマッチしたRDBを運用・構築できるようになりましょう。
また、データベースを用いたデータの集計・加工・前処理などでお困りの方には、データ人材常駐支援サービス「DX-Accelerator」がおすすめです。
データ人材常駐支援サービス「DX-Accelerator」では、データの収集から分析・可視化に至るまでデータ活用関連のお悩みを独自の教育カリキュラムを履修したアナリティクスエンジニアが解決しています。興味がある方は、こちらの記事をご覧ください。
自社が保有しているデータを効率良く利活用し、競合他社に負けない企業を目指しましょう。